
搜尋引擎已成為我們生活中不可或缺的一部分。我們透過輸入關鍵字,就能找到想要的資訊,像是新聞、美食、產品評價等等。然而,傳統的搜尋引擎大多採用 Lexical Search 的方式,而應用這種技術的搜尋引擎並無法提供精確的資訊。以下我們就來一起來了解,如今的主流搜尋引擎,如Google、Bing等,是使用什麼方式來解決以前的搜尋問題。
什麼是詞彙搜尋 (Lexical Search)?
在理解最新的搜尋技術之前,我們必須先知道傳統的搜尋引擎的運作方法,也就是「詞彙搜尋」(Lexical Search),其實這項技術不太難想像,也就是只根據字面上的文字匹配程度來尋找結果。
詞彙搜尋會將你的搜尋詞彙分解成單字,然後在資料庫中尋找包含這些單字的內容。例如,你搜尋「台北美食」,搜尋引擎就會找出包含「台北」和「美食」這兩個詞彙的網頁。
但這種方法卻存在著一些嚴重的缺陷。它只關注文字的表面,而忽略了背後的意義。試想以下幾個例子:
- 搜尋「台灣總統」,卻只找到關於歷任總統的資料,而沒有關於現任總統的資訊。 這可能是因為你搜尋的資料庫中沒有包含「現任」這個詞彙,或者資料庫的更新速度不夠快。
- 搜尋「如何製作蛋糕」,卻只找到一些關於蛋糕種類的介紹,而沒有找到實際的製作步驟。 這可能是因為你搜尋的資料庫中沒有包含「製作步驟」這個詞彙,或者你搜尋的關鍵詞不夠精準。
以上這些例子都說明了詞彙搜尋的局限性。它無法理解人類語言的複雜性,也無法掌握文字背後的深層意義。因此,當你搜尋的關鍵詞不夠精準,或者資料庫中缺少某些關鍵詞時,詞彙搜尋就很容易失效,無法找到你真正想要的資訊。
什麼是語義搜尋 (Semantic Search)?
為了克服詞彙搜尋的缺陷,一種更先進的搜尋技術應運而生,那就是「語義搜尋」(Semantic Search)。語義搜尋不再僅僅關注文字的表面,而是深入探討文字的深層意義,理解詞彙之間的關係和語境。
語義搜尋的核心技術之一就是「詞彙嵌入」(Word Embedding)。詞彙嵌入將文字轉換為數學向量,也就是一串數字。這些數字代表著詞彙的意義,並且能反映詞彙之間的相似性。
詞彙嵌入的原理是,透過大量文字資料的訓練,學習到詞彙之間的關係和語境。例如,在訓練過程中,如果「蘋果」和「香蕉」經常出現在相同的句子中,那麼它們的向量就會比較接近。反之,如果「蘋果」和「汽車」很少同時出現,那麼它們的向量就會比較遙遠。
透過詞彙嵌入,語義搜尋可以理解詞彙之間的關係,並根據你的搜尋意圖,找到最相關的資訊。例如,你搜尋「如何製作蛋糕」,語義搜尋可以理解你想要找的是蛋糕的製作步驟,而不是蛋糕的種類。因此,它會優先搜尋包含「製作」和「步驟」的網頁,而不是只包含「蛋糕」的網頁。
詞彙嵌入是語義搜尋的基礎,它為我們提供了一種新的方式,讓我們能更有效地理解和搜尋資訊。
語義搜尋如何運作
了解了詞彙嵌入的概念後,我們來看看語義搜尋是如何實際運作的。其中一種常用的方法叫做「最鄰近搜尋」(Nearest Neighbor Search)。
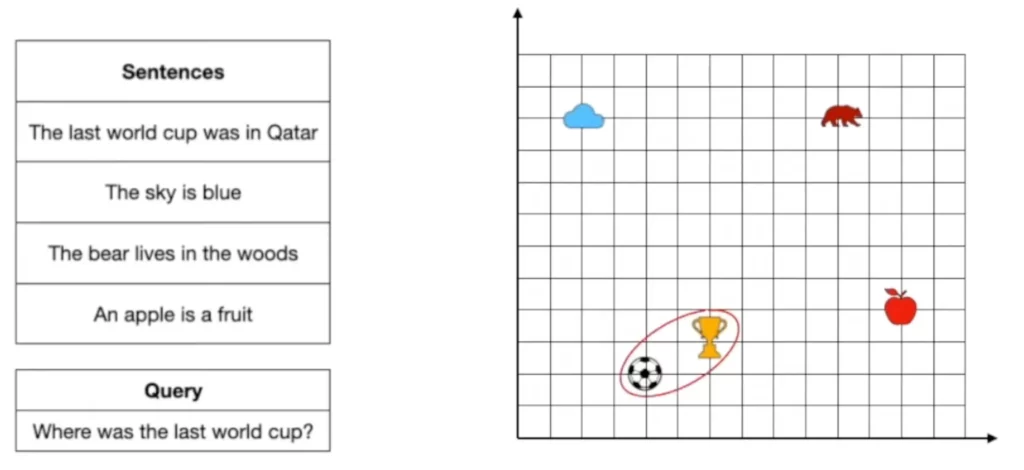
想像一下,你的搜尋問題就像一個點,而資料庫中所有的句子或文件也都是空間中的點。最鄰近搜尋的目標,就是找到與你的搜尋問題最接近的點,也就是最相關的句子或文件。
舉例來說,你想搜尋「最近的世界盃在哪裡舉辦?」,語義搜尋會將這個問題轉換成一個向量,並在資料庫中尋找與這個向量最接近的句子。
這時候,詞彙嵌入就發揮了關鍵作用。 因為詞彙嵌入已經將所有的句子或文件都轉換成了向量,並且根據它們的語義相似度進行了排序。所以,語義搜尋只需要計算你的搜尋問題向量與資料庫中所有句子向量的距離,就能找到最接近的鄰居。
而這個「最近的鄰居」,就是你想要的答案。
讓搜尋更快更精準
雖然語義搜尋在理解文字意義方面有著顯著的優勢,但它也面臨著一些挑戰。其中一個關鍵問題,就是效率。
當資料庫非常龐大的時候,要計算你的搜尋問題向量與資料庫中所有句子向量的距離,就需要大量的運算資源和時間。這就像在一個充滿數百萬顆星星的夜空中,想要找到離你最近的那顆星星,你需要逐一計算每顆星星與你的距離,這顯然不是一個高效的方式。
因此,為了提高語義搜尋的效率,研究人員不斷探索各種方法,希望能夠在不影響準確性的前提下,減少計算量。
其中兩種常用的方法是:
- Inverted File Index: 它會先將資料庫中的所有句子或文件進行分組,將具有相同語義的句子或文件歸類到同一組別。然後,當你搜尋問題時,系統會先找出和你的搜尋問題語義相關的組別,再在這個組別中進行最近鄰近搜尋。這樣一來,就只需要計算一小部分句子或文件的距離,就能找到最接近的鄰居。
- Hierarchical Navigable Small World: 這是一種更複雜的技術,它將資料庫中的句子或文件按照語義相似度進行分層,形成一個樹狀結構。當你輸入搜尋問題時,系統會從樹狀結構的根節點開始,逐層尋找包含你的搜尋問題相關語義的節點,直到找到最接近的鄰居。這種方法的好處是,它可以根據你的搜尋問題的精確度,調整搜尋深度,從而提高搜尋效率。
打破語言的鴻溝
你是否曾想過,能用中文搜尋英文資料,或者用日文找到法文的答案? 語義搜尋的魅力不僅在於理解文字的意義,更在於打破語言的隔閡,讓搜尋變得更加自由和無所不在。
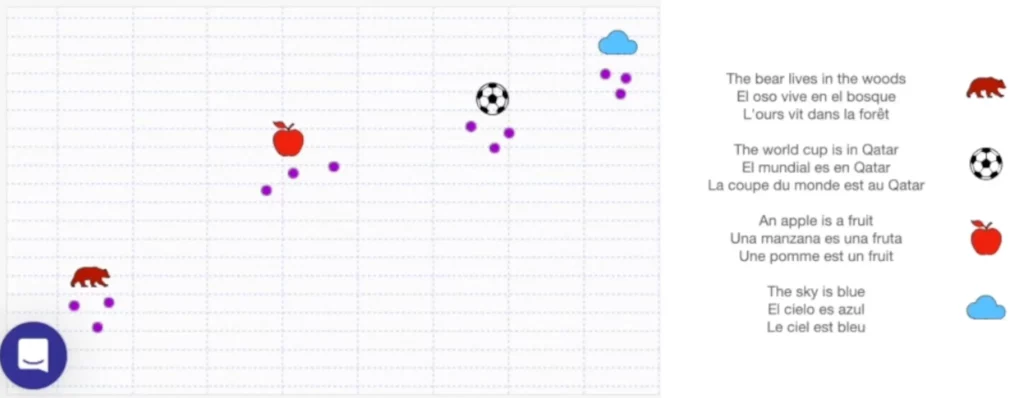
這項突破性的進展,得益於「多語言詞彙嵌入」(Multilingual Word Embedding)的誕生。多語言詞彙嵌入將不同語言的詞彙嵌入到同一空間中,讓不同語言的詞彙能夠互相理解和比較。
想像一下,一個巨大的空間中,包含了世界各國的詞彙,它們按照語義相似度進行排列。當你用中文搜尋「蘋果」時,系統可以找到與「蘋果」語義最接近的英文單詞 “apple”、日文單詞 “リンゴ”、法文單詞 “pomme” 等等。
多語言詞彙嵌入的應用,就像建造了一座跨越語言的橋樑,讓不同語言的使用者能夠相互理解和交流。舉例來說,你想要尋找關於法國美食的食譜,可以使用中文搜尋 “法國美食食譜”,語義搜尋引擎就能夠找到法文寫成的食譜,並將其翻譯成中文,讓你輕鬆閱讀和理解。
讓搜尋更貼近你的意圖
雖然語義搜尋已經取得了巨大的進步,但它依然在不斷進化,追求更加精準、更加貼近人類意圖的搜尋結果。
我們可以將語義搜尋比喻成一個越來越聰明的助手,它不僅能理解你的問題,還能根據你的意圖,找到最適合你的答案。而為了讓這個助手變得更加智慧,研究人員開發了以下的技術。
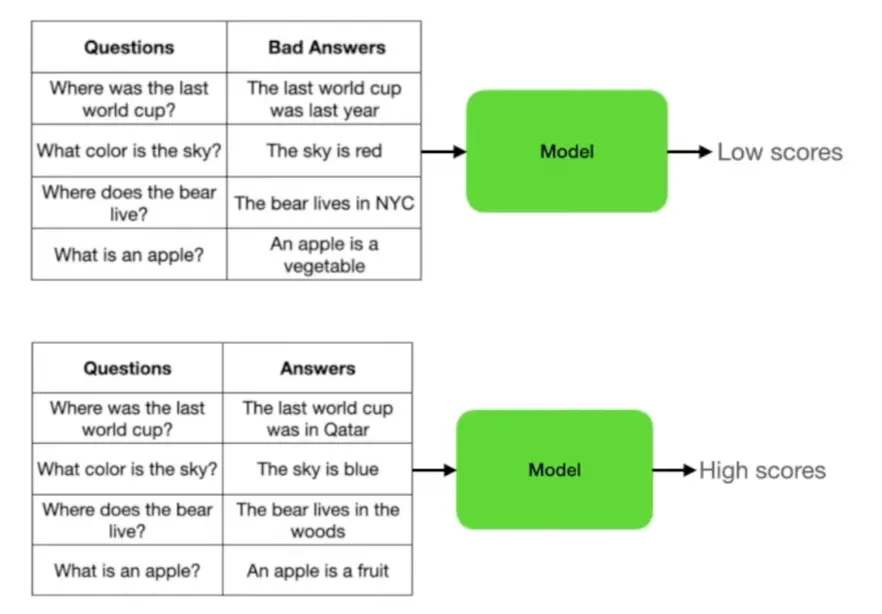
重新排序(Re-ranking)
在最鄰近搜尋的基礎上,重新排序技術會利用另一個模型來評估搜尋結果的準確度。這個模型通常會使用大量已知的問答對進行訓練,學習哪些答案是正確的,哪些答案是錯誤的。當你輸入問題時,系統會先使用最鄰近搜尋找到一些初步的答案,然後再使用重新排序模型對這些答案進行評估,選出最準確的答案。
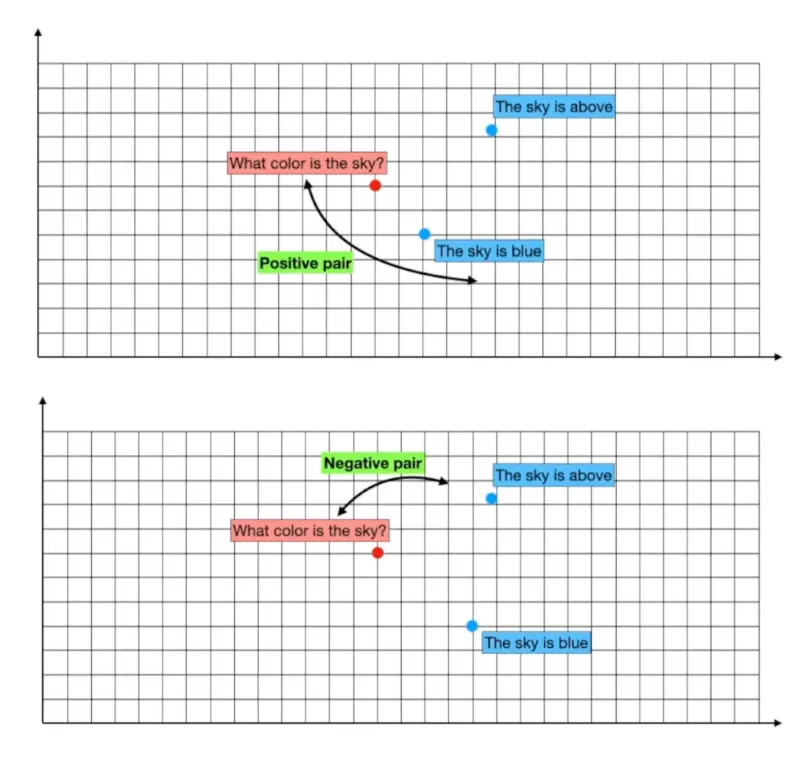
正負樣本組合(Positive and Negative Pairs)
這是一種訓練詞彙嵌入模型的技巧。它會將正確的問答組合視為正樣本,而將錯誤的問答對視為負樣本。在訓練過程中,系統會不斷調整詞彙嵌入模型,讓正樣本(Positive Pair) 的向量更接近,而負樣本(Negative Pair)的向量更遠離。這樣一來,詞彙嵌入模型就能夠更好區分正確答案和錯誤答案,提高搜尋結果的準確性。
結論
從傳統的詞彙搜尋到如今的語義搜尋,我們正經歷著一場資訊搜尋的革命。語義搜尋不再僅僅停留在文字的表面,而是深入探討文字的深層意義,理解詞彙之間的關係和語境,為我們帶來更加準確、更加貼近意圖的搜尋結果。
然而,語義搜尋的發展依然在繼續。語義搜尋將會融合更多的人工智慧技術,例如自然語言處理、知識圖譜等等,讓它變得更加智能化、更加人性化。我們可以期待,語義搜尋將會成為我們生活中的重要助手,幫助我們更有效地獲取資訊,更便捷地解決問題,讓我們的日常生活更加美好。
