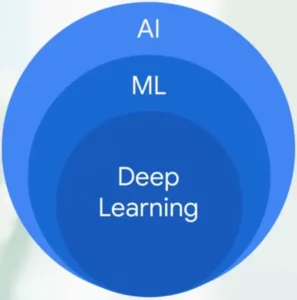
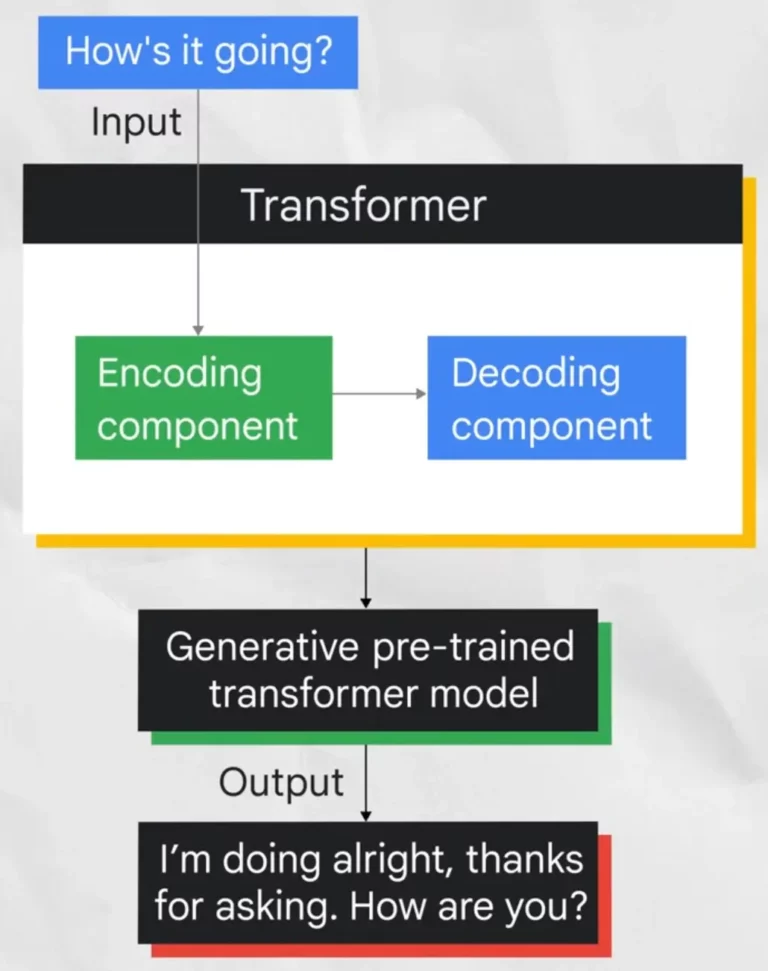
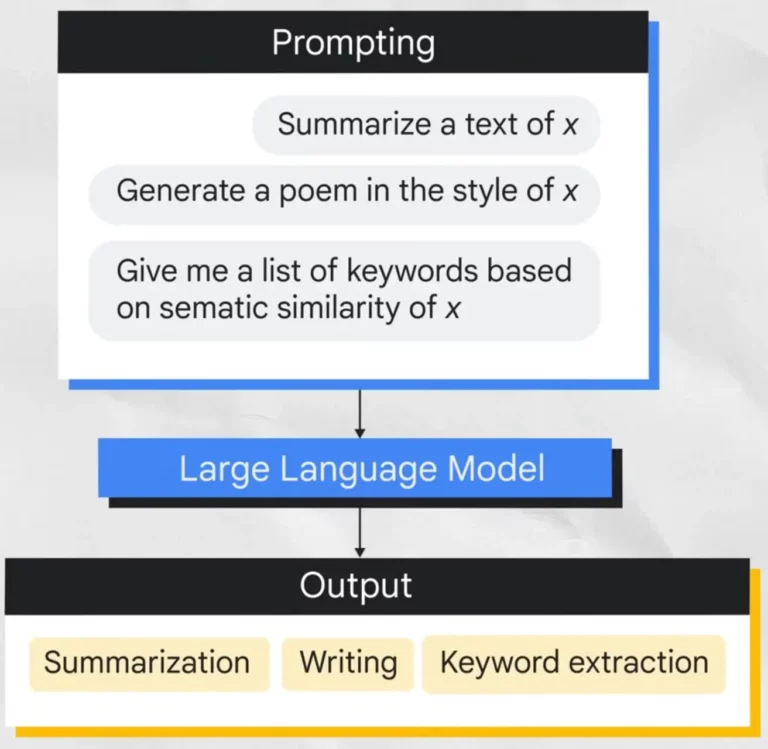
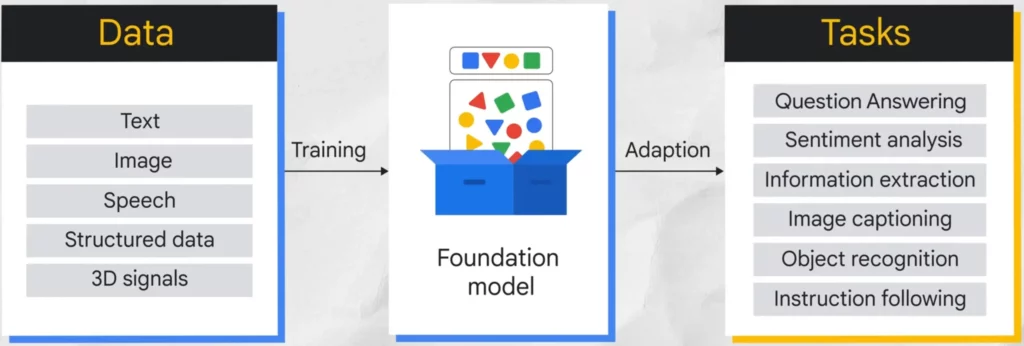
此外,基礎模型(Foundation Model)是近年來興起的一種新型生成式 AI 模型。它們在海量數據上進行預先訓練,可以適應各種不同的下游任務,例如:
情感分析:分析文字的所富含的情感,例如判斷一篇文章是正面、負面還是中性的。
圖像描述:為圖像生成文字描述,例如描述一張圖片中的物體、場景和人物動作。
物體識別:識別圖像中的物體,例如判斷一張圖片中是否有貓、狗或汽車。
基礎模型 (Foundation Model)
Lewis Ko
Hi 我是Lewis,曾任職in-house行銷人員,現職某跨國企業的SEO Specialist。熱愛學習最新的科技和知識,努力透過簡單易懂的方式,分享我學習的過程和心得。如果你/妳剛好也在學習 搜尋引擎最佳化、Google Analytics 4、Google Tag Manager、Google Looker Studio,希望我的內容對你有幫助!