理解網頁檢索和索引對於優化搜尋引擎排名至關重要,因此本文將深入探討一項 Google 專利中所描述的網頁檢索與索引系統,包含解析該系統工作原理和其背後的設計概念。
- 專利名稱:ANCHOR TAG INDEXING IN A WEB CRAWLER SYSTEM
- 專利代號:US20160321252A1
- 專利申請者: Google Inc.
專利充滿許多專有名詞,由於內容篇幅及可閱讀性等考量,無法在內文中詳細解釋。如果對技術細節有興趣,請前往最下方的段落。
Google 如何進行檢索?
URL Scheduler
URL 排程器 (URL Scheduler) 是該系統的第一步,它決定了哪些 URL 需要在特定的時段內被檢索。
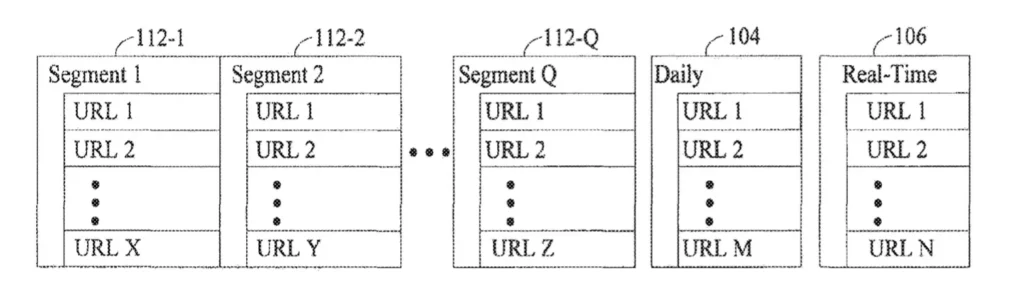
系統將這些 URL 分為三個層級:
基礎層 (Base Layer):這是所有被索引的URL 的集合處,通常包含網站上較為穩定且不常更新的內容。這些 URL 可能不需要頻繁檢索,因此被歸類在這個層中。
每日檢索層 (Daily Crawl Layer):這個層級的 URL 包含那些經常更新的頁面,比如新聞網站或部落格。這些 URL 可能每天都會發生變動,因此需要更頻繁檢索和索引。
即時層 (Real-Time Layer):這是最高優先級的 URL 層,通常包括那些需要即時更新的頁面,如社交媒體動態或突發新聞。這些 URL 需要非常頻繁被檢索,甚至可能在一天內被多次索引。
URL Manager
在 URL 排程完成後,URL 管理器 (URL Manager) 會接手將 URL 分發給多個自動化爬蟲 (也稱作 Googlebot),這些爬蟲會按照排程對 URL 進行檢索。管理器還會根據每個 URL 的層級來決定檢索順序,確保最重要的 URL 能夠被及時處理。
檢索優先順序
你是否很好奇,搜尋引擎如何決定一個頁面的檢索頻率?
在這個專利中,明確了解釋背後的原理:「The decision as to whether to add or remove URLs from daily layer and real-time layer is based on information in history logs that indicates how frequently the content associated with the URLs is changing as well as individual URL page ranks that are set by page rankers.」。
此外,專利又提到一個名為 Crawl Score 的分數,並且說明這個值是用來決定在特定的檢索週期(epoch) 內應優先檢索哪些 URL。當無法在一個週期內檢索所有 URL時,這個分數用來確保只有最重要的 URL 可以被優先檢索。
以下是計算公式:

簡單來說,檢索頻率取決於:
change frequency:透過分析歷史記錄 (History Log),系統會判斷特定 URL 的內容更新頻率。更新頻繁的 URL,例如新聞網站或社群媒體動態,更有可能被分配到即時更新層,確保搜尋結果能反映最新資訊。反之,較少更新的 URL 則可能被分配到每日更新層。
page rank:網頁排名也是重要考量因素。網頁排名是由 Page Rankers 根據多種因素評估,例如網站權威性、連結品質等等。高網頁排名的 URL 通常代表著更高的重要性和可信度,因此更有可能被優先收錄到即時更新層,讓使用者更快找到這些重要資訊。
- time since last crawl:自上次檢索以來經過的時間。
Robots
當 URL 管理器完成分配後,Googlebot 將開始執行檢索任務。這些爬蟲會開始前往各個 URL 下載其內容,並將其傳送給內容過 濾器 (Content Filter) 進行進一步處理。
爬蟲不會檢索嵌入式或永久轉址內容,而是專注於下載該頁面的內容,這樣可以避免不必要的負擔。
Google 如何完成索引?
錨點標籤與文字
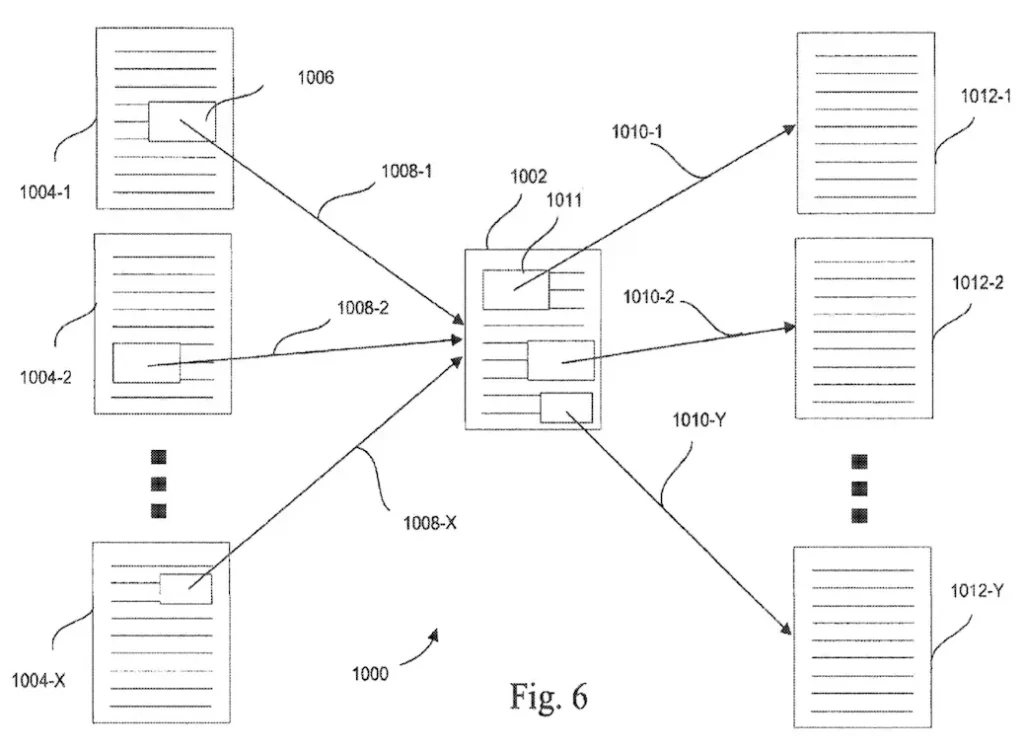
當 Googlebot 下載網頁時,它會收集頁面上連結的資訊。每個連結通常包含一個錨點標籤 (Anchor Tag)、可點擊的文字和將會導向的 URL。
不僅如此,它還會一併蒐集錨點文字周圍的上下文。這一功能對於理解連結的完整意圖至關重要,尤其是在目標頁面本身缺乏明確描述。
處理非文字內容
對於圖像、影片這些缺乏文字內容的頁面,索引和排名他們對 Google 來說始終是一個難題。
然而,如同專利中所述:「some types of web pages (e.g., image files, video files, programs, and so on) contain little or no textual information that can be indexed by a text-based index.」,透過使用與錨點文字和周圍的上下文,搜尋引擎可以更容易理解並索引這些頁面。
錨點文字的註解與屬性
Googlebot 還會捕捉錨點文字的屬性,這些屬性可能是加粗體、引用符號或程式碼的一部分。這些屬性與錨點文字都會一併被儲存,並用於提高連結頁面的相關性評分。
例如,如果一個錨點文字使用在 <strong> 標籤內,系統會將其視為更具重要性,從而在搜尋結果中賦予該頁面更高的權重。
Link Log 與排序錨點圖
爬蟲下載完相關資訊後,系統會將這些資訊記錄在 Link Log 中,它會紀錄連結所在的頁面、連結指向的頁面以及與該連結相關的錨點文字。
接下來,系統會根據 Link Log 的這些連結資訊,自動組織成一個排序錨點地圖 (Sorted Anchor Map)。這個地圖說明了每個目標頁面與其來源頁面之間的關係。
這不僅能夠使搜尋引擎更好理解目標頁面的內容,還能根據外部頁面的描述提高搜尋結果的準確性。
Global State Manager
全局狀態管理器 (Global State Manager) 負責處理這些 Link Log,並將其轉換為 Link Map 和Anchor Map。
- Link Map 根據連結的來源和連結的目標進行處理。
- Anchor Map 則將連結的錨點文字與相應的 URL 進行匹配
這些地圖最終會被用來構建搜索引擎的索引。
全域狀態管理器 (Global State Manager) 是整個系統的核心組件之一,負責從連結紀錄中讀取資料,並生成連結地圖 (Link Maps) 和錨點地圖 (Anchor Maps)。這些地圖被頁面排名器 (Page Rankers) 用來調整 URL 的頁面排名,並由索引器 (Indexers) 用來構建搜尋引擎的索引。
Real-time Log
Real-time Log 則是另一個系統關鍵組件,它儲存了網頁的內容以及其 PageRank。這些數據最終會被用來創建可被搜尋的索引,並部署到搜索引擎的伺服器上,供終端用戶搜索使用。
這樣的索引過程不僅保證了搜索結果的精確性,還能讓用戶找到的資訊都是最新的。
處理重複內容
重複內容對 Google 來說是一個大問題,因為當出現重複內容時,搜尋引擎無法確定哪個版本是最原始、最具權威的。
這可能導致搜尋結果中出現多個相同或相似的內容,不但降低了使用者體驗還浪費了檢索資源。因此我們也在專利中找到,這個系統是如何解決這個問題。
網址與內容處理
當系統中的機器人 (Robots) 從網路上抓取內容時,這些內容首先會通過內容過濾器 (Content Filters) 進行初步處理。內容過濾器的主要功能是檢查抓取到的內容是否與上次檢索的版本不同,這樣就可以避免對於未更改的內容進行不必要的索引。
檢測重複內容
在初步處理之後,內容被傳送至 DupServer,這是一個專門用來檢測重複內容的模組。DupServer 的核心功能是通過比較內容的指紋 (Content Fingerprints),來判別內容是否有重複。
DupServer 會分析每個頁面的內容指紋,並將其與系統中已經存儲的其他頁面的指紋進行比較。如果發現相同的指紋,就意味著這些頁面是重複的,可能來源於不同的 URL 但包含相同的內容。
標準化
一旦 DupServer 確定了頁面內容有重複,下一步是決定哪一個頁面應該被保留作為主要頁面 (Canonical Page)。主要頁面通常是系統認為最具代表性或最權威的版本,它將被保留並進行索引,而其他重複頁面則會被排除。
在這個過程中,系統會比較每個重複頁面的頁面排名 (PageRank),通常會選擇排名最高的頁面作為標準頁面。非主要頁面則不會被索引,但其資訊會被記錄在 History Log 和 Status Log 中,這些 Log 記錄著頁面的狀態以及它們為什麼被排除在索引之外。
存儲紀錄
系統中會使用多個 Log 來記錄頁面處理的詳細資訊,其中 History Log 和 Status Log 是處理重複內容的關鍵。當DupServer 標記一個頁面為重複內容時,該頁面會被記錄在這些 Log 中,但不會進一步處理或索引。
Host Duplicate Detection
專利中同時也提到了一個名為 Host Duplicate Detection Module 的模組,它會分析多個域名或子域名,確定它們是否在提供相同的內容。如果發現重複內容,系統會選擇其中最具代表性的版本進行索引,並忽略其他版本。
舉個例子,如果一個網站的主域名(如example.com)和它的一個子域名(如blog.example.com)都提供了相同的文章內容,那麼這個模組可能會判斷出這兩個頁面是重複的,並選擇僅索引其中一個。
重新導向處理
網頁重新導向 (Redirect) 是網站在搬遷或改版時經常使用的技術,將舊的 URL 導向新的地址,確保用戶和搜尋引擎能夠找到正確的頁面內容。
而該系統在處理轉址時,能夠區分出是「臨時轉址」還是「永久轉址」,並作出相應的處理。
301 永久重新導向
當 Googlebot 遇到 301 永久重新導向時,它會將原始 URL 和轉址後 URL 的資訊傳送到內容過濾器 (Content Filters),過濾器會將轉址資訊記錄在 Link Log 中,並傳送給 URL 管理器 (URL Manager)。最終,系統會將轉址後的 URL 視為主要 URL (Canonical) 並納入索引,而原始 URL 則不再被索引。
302 臨時重新導向
對於 302 臨時重新導向,系統會繼續索引原始 URL 並前往其轉址的連結,但不會替換原始 URL。在這種情況下,原始 URL 和轉址後的 URL 都會保留在索引中,確保無論轉址是否穩定,都不會影響搜尋結果的準確性。
伺服器架構與負載管理
模塊化伺服器架構
該系統的另一個亮點是其模塊化伺服器架構。不同的功能被分佈在多個專用伺服器上運行,例如 URL Manager、Global State Manager 和 Indexer 各自在獨立的伺服器上執行。這種設計不僅提升了系統的可擴展性,還使得資源的分配更加靈活。
在流量激增的情況下,系統可以通過增加伺服器來應對這樣的問題,確保檢索和索引過程不會受到影響。
主機負載伺服器與預訂系統
為了避免單一伺服器的過載問題,系統引入了主機負載伺服器和預訂系統。URL Server 會向主機負載伺服器請求下載許可,這些許可是根據當前主機的負載情況而授權的。
例如,當多個機器人同時嘗試造訪某個網站時,主機負載伺服器會確保這些請求不會超過該網站的承載能力,從而避免造成網站性能問題。
DNS 增強技術
系統還包括 DNS 解析增強技術,這意味著它能夠快速解析 URL 對應的 IP 地址,而不依賴於外部 DNS 伺服器。系統內部的本地 DNS 數據庫儲存了過去檢索的 URL 對應 IP 地址,使得 URL 的解析速度大幅提升,進一步優化了檢索效率。
系統核心組件解析
為了提高檢索和索引效率,專利中提到,有許多核心組件在系統中分工合作。以下就一起來深入了解各個核心組件的功能吧!
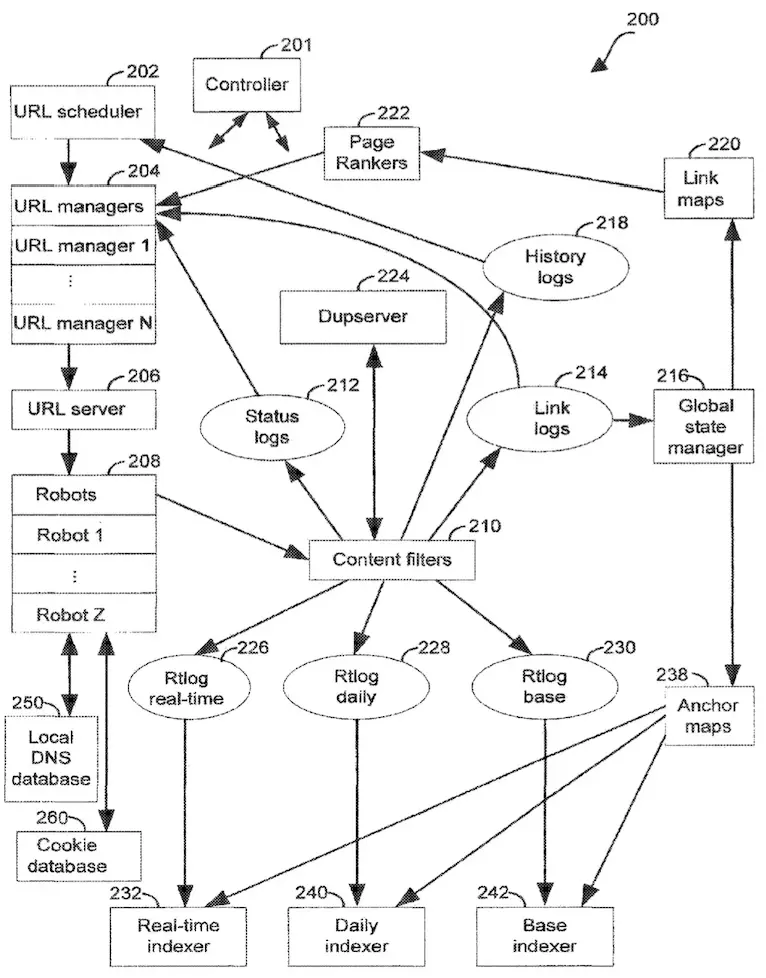
URL Scheduler
URL 調度器 (URL Scheduler) 在系統中扮演著關鍵角色,它負責決定哪些 URL 會在每個週期內被檢索,並將這些資訊儲存在資料庫中。調度器會根據每個 URL 的內容更新頻率和頁面排名,動態調整 URL 應該在哪一個索引層級。
URL Managers
URL 管理器 (URL Manager) 負責處理來自 URL 調度器的層級資料。管理器通常被部署在專用伺服器上,確保能夠處理大量的URL 資料。URL 管理器還會偵測連結紀錄 (Link Logs) 以發現新的URL,並將這些新發現的 URL 加入管理器的哈希表中,以便後續檢索。
URL Server
URL 伺服器 (URL Server) 的主要負責從 URL 管理器那裡接收 URL 並將它們分配給機器人(Robots) 進行檢索。
URL伺服器會根據一套策略來造訪特定類型的 URL,例如新聞等,並將這些 URL 分配給適當的機器人進行處理。這確保了每個 URL 管理器都能有效參與到檢索過程中。
Content Filters
內容過濾器 (Content Filters) 負責處理機器人檢索到的頁面,並將相關資訊傳遞給其他系統組件。例如,過濾器會檢查頁面是否為重複內容,如果是,則不會將其傳遞給索引器進行索引,而是將其標記為 Duplicate。此外,內容過濾器還會將頁面資訊寫入不同的紀錄中,如連結紀錄 (Link Log)、歷史紀錄 (History Log) 和狀態紀錄 (Status Log)。
Robots
機器人 (Robots) 是自動抓取網頁的程式,它們依據 URL 伺服器分配的 URL 進行檢索。與普通的網頁瀏覽器不同,機器人不會自動檢索嵌入在網頁中的多媒體內容 (圖片、影片等),而是專注於抓取文字和超連結。此外,機器人也不會追蹤永久重新導向 (Permanent Redirect) 的URL,而是將這些 URL 記錄到 Link Log 中,供後續處理。
DupServer
重複內容伺服器 (DupServer) 負責偵測並處理重複的網頁內容。當一個頁面被判定為與其他頁面重複時,DupServer 會比較這些頁面的排名,並將其中最重要的頁面設為主要頁面 (Canonical)。而重複頁面將不會被索引,只會在留下記錄。
Global State Manager
全域狀態管理器 (Global State Manager) 是整個系統的核心組件之一,負責從連結紀錄中讀取資料,並生成連結地圖 (Link Maps) 和錨點地圖 (Anchor Maps)。這些地圖被頁面排名器 (Page Rankers) 用來調整 URL 的頁面排名,並由索引器 (Indexers) 用來構建搜尋引擎的索引。
Page Rankers
頁面排名器 (Page Rankers) 負責計算 URL 的頁面排名 (PageRank),這一過程不僅考慮指向該 URL 的連結數量,還會考量這些連結頁面的排名。這種排名方法,確保搜尋引擎能夠根據 URL 的重要性進行排序,從而提高搜尋結果的相關性。
Indexers
索引器 (Indexers) 負責將來自 Real-tine Logs 的網頁進行索引,並生成使用者可以搜尋的索引檔案。這些索引一旦生成,對應的文件就會成為可搜尋的內容,能夠被前端查詢系統 (google.com) 快速檢索。
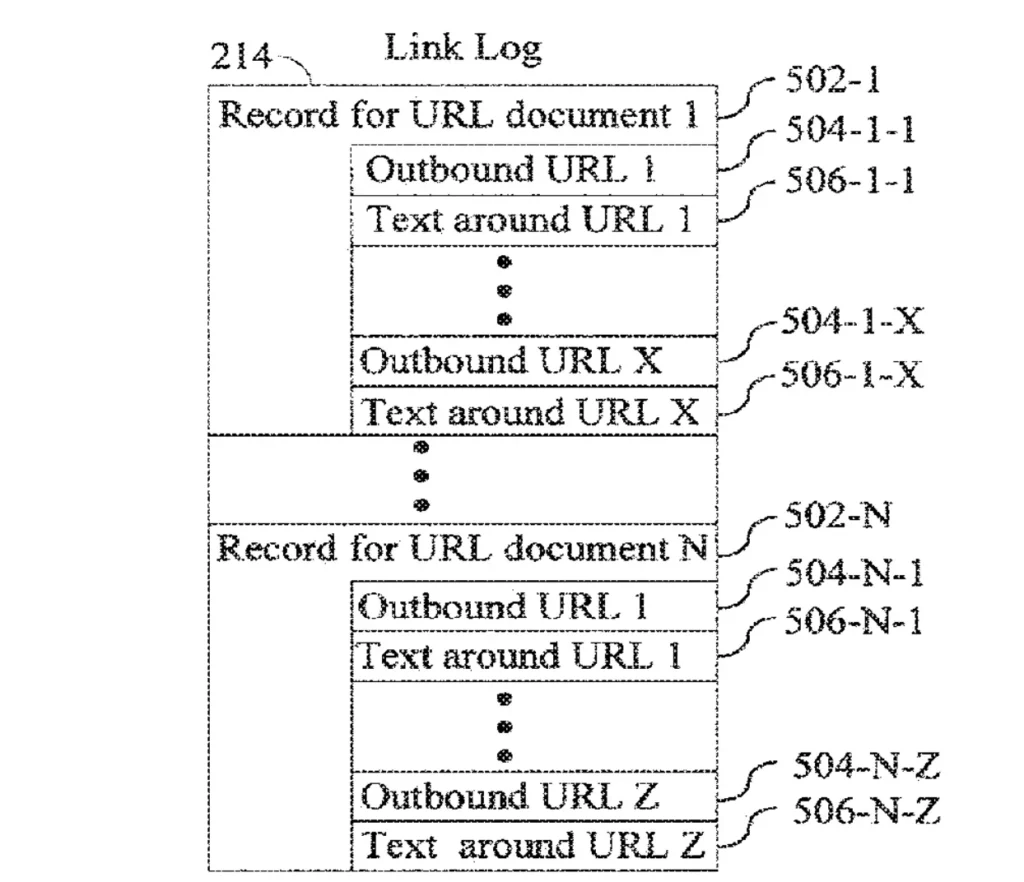
Link Log
連結紀錄 (Link Log) 包含每個從 URL 獲取的內容記錄。每條記錄包括:
- 外部連結:網頁上指向其他 URL 的連結。
連結周圍的文字:能幫助系統理解連結指向的頁面可能涉及的主題或內容。
這些記錄被分佈在多個伺服器上,以便內容過濾器能夠以非常快的速度將數據寫入 Link Log。
State Log
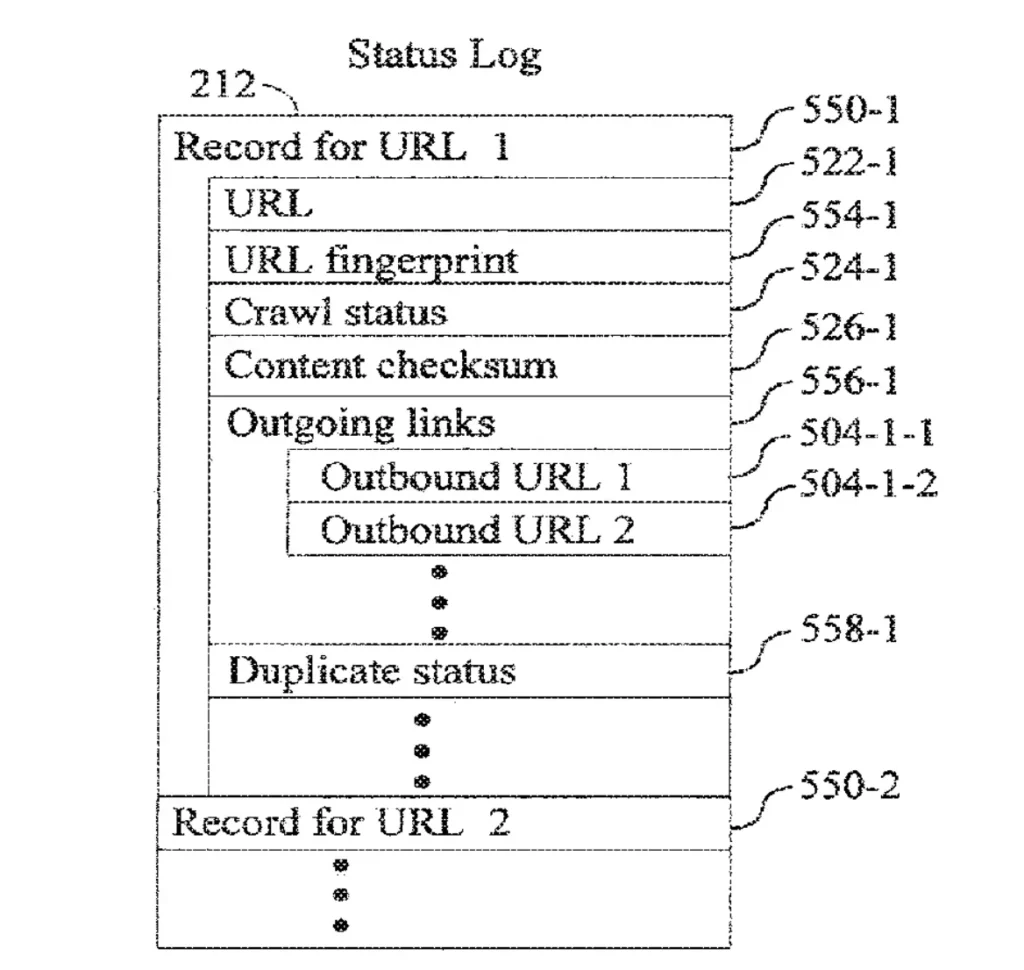
狀態紀錄 (State Log) 是由內容過濾器所生成的有順序的紀錄,它記錄了每個 URL 的完整狀態,包括:
- URL fingerprint:一個為每個URL 創建的唯一識別碼。可以將它看作是一串數字,幫助系統識別並區分每個URL。
- Crawl status:該 URL 是否已被爬取、何時被爬取過。
- Content checksum:像是網站內容的指紋。如果兩個網站的內容相同,它們會有相同的指紋。系統會將當前的指紋與上次訪問該網站時的指紋進行比較,以查看內容是否發生了變化。
- Outgoing links:網頁上指向其他URL 的連結。
- Duplicate status:該 URL 的內容是否與其他 URL 重複,以及是否被標記為重複內容。
這些狀態紀錄用於跟蹤每個 URL 的檢索過程,並確保在後續檢索中能夠即時更新。
Real-time Log
實時紀錄 (Real-time Log) 儲存了:
- Document:爬蟲在瀏覽和檢索網路時,從各個網站上下載的網頁內容。
- Page rank:被賦予每個網頁的一個排名分數。
系統會將這些網頁和其 Page rank分散存儲在多個服務器上,以確保數據可以非常快速存取。

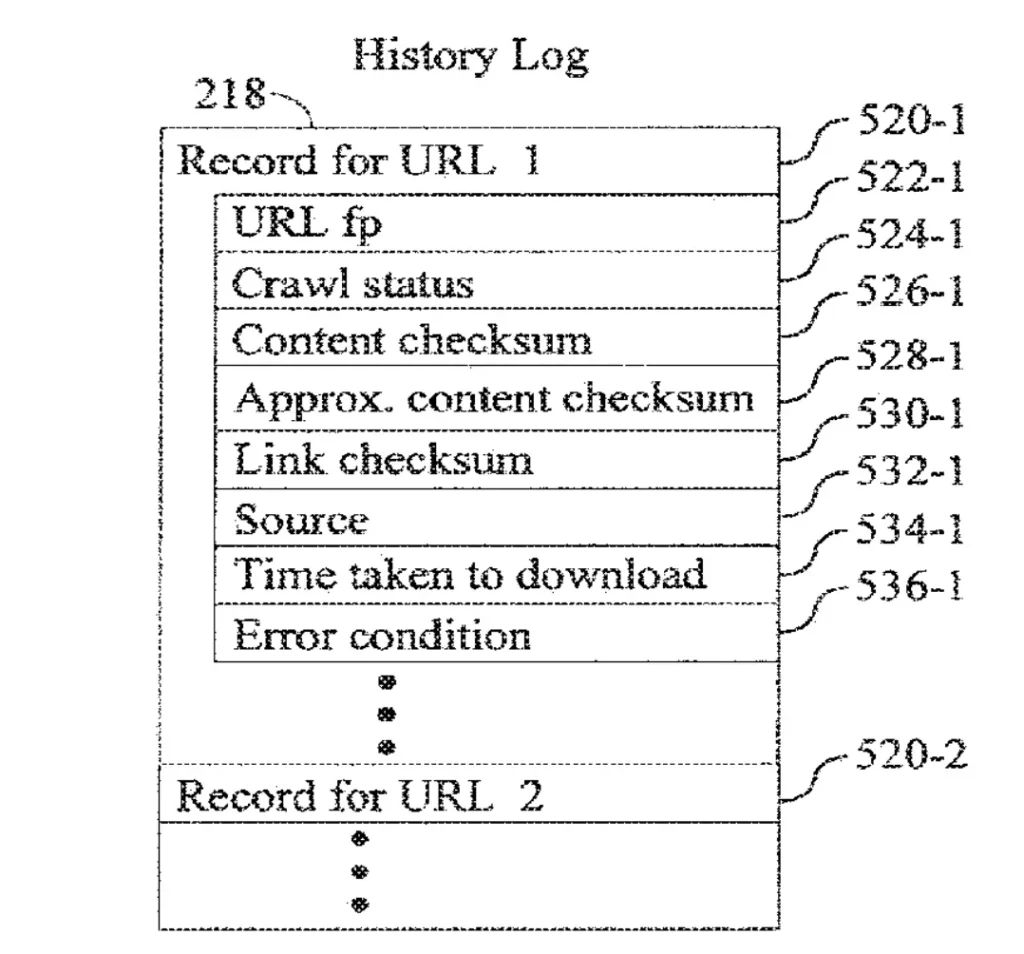
History Log
歷史日誌 (History Log) 記錄了每個 URL 的檢索歷史,包括:
- Crawl status: 顯示該網站是否被機器人成功訪問。
- Content checksum:像是網站內容的指紋。如果兩個網站的內容相同,它們會有相同的指紋。系統會將當前的指紋與上次訪問該網站時的指紋進行比較,以查看內容是否發生了變化。
- Link checksum:檢查網站上的任何連結自上次訪問以來是否有更改。
- Source:指示機器人是從網路還是內部資料庫訪問該網站。
- Time taken to download: 記錄機器人下載該網頁所花費的時間。
- Error condition:記錄機器人在嘗試訪問網站時遇到的任何問題,例如 HTTP 404 錯誤。
這些紀錄幫助系統判斷網頁是否在上次檢索後發生了變化,並根據需要調整檢索頻率。